Machine Learning and its expanding technology horizons
feb 19,2018
A new age of technology capable of surpassing the human brain capacity is evolving at a very fast pace. The horizon is broadening day by day, as these technologies develop use cases in a creative manner. 2017 has already witnessed a huge leap in Artificial Intelligence and Data science, though is more left than done.
You may have seen the practical implementations of it in fields, like:
- Granular Level mining of data to identify the shopping behavior.
- Machine learning capabilities of Chatbots has simplified the sale and marketing trends.
Wondering how it happens?
Mainly, the aspects of Machine Learning and Deep learning are all governed by the evolution of AI. Basics of mathematics, technology and science are bound together to infer valuable information, from the immense data available.
To start with, do you know what Machine Learning is and how it works?
If not, and you willing to learn its working basics, it will take as much time as you will take in finishing to read this article.
What is Machine Learning?
Learning is a human quality. That’s what makes us ‘intelligence’. When it comes to machines, they are speedy but not intelligent. They need instructions, every time when something is to be done. That’s where we want automation. To automate the machines, it is very much required that they first ‘learn’ to keep learning. And the concept of Machine Learning strikes in right here.
Machine learning is an application that derives itself from the roots of artificial intelligence (AI). It makes the machine inherently capable of learning and improving over the interactions. Machines are made capable of doing operations and handling deriving information from the data available while they learn from each operation they perform.
The machines observe data, understand it, assimilate it and make decisions based on it. In future, the decisions are going to be better as the machine is learning. All this happens without any human interventions.
Benefits and Applications of Machine Learning
Real-Time rapid processing & predictions
Machine learning algorithms replicate the human brain and its neural network. With the advancements, Machine learning is processing at much-accelerated levels now. Massive data analysis capacity within fractions of seconds and yielding very accurate predictions has made machine learning and indispensable technology for every business. Capable of identifying fine details and processing the same at very fast speeds ML is making predictions for small businesses to huge enterprises.
Providing leads on conversions and ROI’s, analyzing the spending patterns of the customers and all such types of tasks are being performed by Machine learning algorithms.
Error-free data entry
Human errors in data entries cause issues in corporate setup. Machine learning algorithms contain Data duplication and errors. Using these algorithms makes it simple to automate data entry processes. Predictive analysis, machine learning and artificial intelligence is all integrated to perform tasks done by human to reduce inaccuracies.
Precise Models
Machine Learning is stepping into the sensitive zone of finance also. The models have been developed to facilitate quick and correct tasks of loan underwriting, detecting frauds, helping investment bankers with portfolio management. Machine Learning algorithms specifically written to work for financial sectors have been trusted by big brands for accuracy, speed and precision.
Detecting Spams
Spams are marring the network speed and unnecessarily consuming the bandwidth. Machine learning algorithms have been made capable of detecting spams and eliminating them just like a human brain does. Developing rules and filtering out spam had never been easy as with Machine learning. This saves a lot of computer network bandwidth, storage issues and virus attacks.
Chatbots
Chatbots are an interesting use case of Machine learning and artificial intelligence. The Chatbots have changed the face of entire marketing industry by very accurately analyzing the customer needs and shopping behavior to answer just like humans. The advent of NLP has revolutionized the customer care voice supports.
How is a machine learning model developed?
Step 1: Choosing/Creating Algorithms
Machine learning model, for any use case, is developed on some algorithms. These algorithms could belong to any of the categories, listed below:
o Supervised Algorithms
Supervised Algorithms are developed that helps machine predict the future events based on the labeled examples from the past experiences. So effectively the Supervised Algorithm trains the machine to infer output on the basis of an existing functionality to offer outputs.
o Unsupervised Algorithms
Unsupervised algorithms are brought to use only when the case to be studied is completely new and not labeled. This phase puts data analysis to good use as the results are derived completely on the basis of data at hand.
o Semi-supervised Algorithms
These algorithms use a part of labeled data and a part of unlabeled data. The machines that work on Semi-supervised algorithms learn over time and become more accurate.
o Reinforcement learning algorithms
Reinforcement learning algorithms are very interactive. It talks to its environment by acting and performs an in-depth errors analysis. It is more of a trial and error learning that offers delayed reward. Reinforcement learning facilitates machines and developed software to automatically find out the ideal behavior that maximizes the performance.
Step 2: Error analysis
While you are building a new machine learning model, you should definitely be ready to face some issues and error analysis plays a vital role. The first step of error analysis is defining the target test set and the bed that evaluates the performance. An error can be evaluated manually and is of two types:
1. Error due to Bias:
The error due to bias is the actual difference between the predicted values from our model and the actual value. While measuring the error, we take a range of data into consideration. Bias is actually a measure of how much the values generated by model vary from the correct value.
2. Error due to Variance:
For bias, we consider the entire set of test data that the model goes through and for variance we talk about each point of test and how the values around that vary between the exact value and the predicted values.
Subtypes of machine learning
Deep learning
Deep Learning is a subtype of machine learning. The concept of deep learning correlates to the neural networks of human brains and drives its structure and function from there. The aspects of Deep learning have evolved drastically since 1999’s.
Today’s deep learning algorithms revolve around the availability of fast computers and immense data that could facilitate the Deep learning algorithm capabilities. Data scientists will be highly benefited by the development on the side of Deep learning.
Larger neural networks are being developed to handle huge data and this also enhances their performance. Feeding more data to Deep learning algorithms make them more capable of predicting correct results.
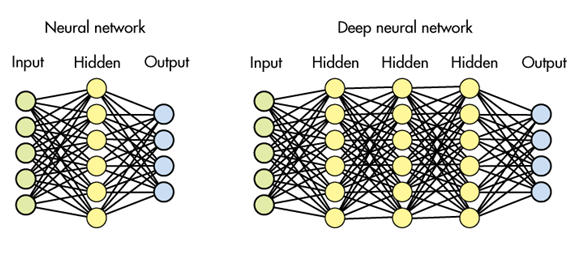
Deep learning is a segment of machine learning algorithms, in which:
- A successive layer of algorithms take the output of the previous layer and extracts features from it.
- It works in both supervisedand unsupervised
The algorithmic layers used in deep learning are actually layers of an artificial neural network that are hidden.
Deep learning algorithms need massive amounts data that is labeled and higher computational power. The parallelism in today’s computer offers an efficient platform for deep learning by substantially reducing the learning time.
What are CNN and rCNN?
CNN (convolutional neural network) is a type of deep neural network that is capable of analyzing 2D images. A Convolutional Neural Network (CNN) is made of one or multiple convolutional layers. The final layer is the one that connects all these neural networks.
CNNs are very easy to train that can infer data from local connections and tied weights that are then pooled together to deliver results. Regional-CNN is the latest visual object detection system. The model combines region proposals with features computed by a convolutional neural network and offers better results.
Difference between Deep Learning and machine Learning
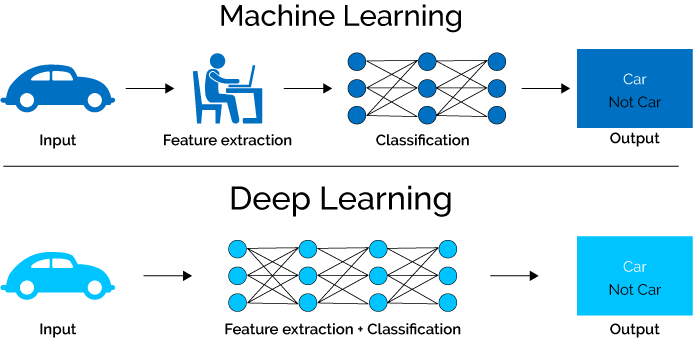
Deep learning is a subform of machine learning. In machine learning, the data is extracted from the images manually. Any machine learning model is created on the basis of these relevant extracted features.
On the contrary, the deep learning model automatically extracts the features from the images. A deep learning algorithm is capable of working on raw data and offers classified outputs.
The biggest advantage of deep learning algorithms is that its intelligence grows with the training and feature extraction while the machine learning reaches a certain plateau and cannot grow from there.
What is t-distributed stochastic neighbor embedding (t-SNE)?
t-SNE is a branch of machine learning that works on the concept of dimensional reduction. With the data becoming massive, the computers are capable of handling it but human brains find these many dimensions too complicated to handle and this is where t-SNE plays a role. It creates simple to infer two-dimensional images from a hundreds of dimensional data.
The algorithm behind it is non-linear and works on the maximum proximity principle that could lead to different results every time.
What is Q-learning?
Q-Learning is a classic example of Off-Policy algorithm. It is the most appropriate algorithm for Temporal Difference learning. With extensive training, the algorithm is capable of reaching probability 1 and delivering very accurate features.
Machine Learning use case – What is Image Classification?
Image Classification is a perfect use case of machine learning. For image classification, human analyst classifies features of an image from the visual interpretations. With the advancements in machine learning, human Analyst has been replaced by machines that extract information from raster images. The classifications are done on the basis of supervised and unsupervised algorithms.
Didn’t get?
When the Facebook tries to count the number of friends in your picture or your laptop suggests you to save the picture with a name tag, the image classification algorithm is running behind the scenes.
Now, if it is a small algorithm which uses its own rules to classify the visuals while not learning anything from the new data it is processing, the algorithm could be considered supervised. On the other hand, if the algorithm can remember your or your friend name once you have made use of it, once or twice, it is an unsupervised and thus, the smarter classification algorithm.
Conclusion
There is always a lot to learn when it comes to data sciences, artificial intelligence, deep learning or machine learning (for the researchers as well as for the machines). So, it is clearly obvious that the horizon of these technologies, its terms and dependent technologies will keep on broadening. The far we will go, the more applications will be found, influencing industries and households in a positive way (most of the times). That’s how, Artificial Intelligence will soon become an inseparable part of our lives. Any doubts about its potential?
Sources / References:
- https://www.mathworks.com/discovery/deep-learning.html
- https://towardsdatascience.com/error-analysis-to-your-rescue-773b401380ef
- https://www.kdnuggets.com/2016/08/bias-variance-tradeoff-overview.html
- https://machinelearningmastery.com/supervised-and-unsupervised-machine-learning-algorithms/
- https://www.geeksforgeeks.org/supervised-unsupervised-learning/
- https://www.rand.org/pubs/research_reports/RR1744.html
- https://arxiv.org/abs/1506.01497